From an implementation point of view, a neural networks can be implemented in two ways: stateful or stateless. The choice of state representation does not change the theory, but certain applications benefit one approach over the other. In this article, I briefly explain the two approaches with examples of how and when to use each.
Stateful Models
Stateful models stored their weights inside the module definition. By default, PyTorch modules are stateful, meaning that when you instantiate an instance of the nn.Module class, the weights of the module are initialized and stored internally. Below, is an example one an MLP with one hidden layer:
import torch
import torch.nn as nn
class StatefulModel(nn.Module):
def __init__(self, input_dim: int, hidden_dim: int, output_dim: int):
super(StatefulModel, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, output_dim)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
# Initialize model
model = StatefulModel(10, 50, 1)
# Random input and prediction
x = torch.rand(1, 10)
pred = model(x)In this example, the layers (fc1 and fc2) are attributes of the class. Each layer maintains its own parameters and buffer, also referred to as its state. The full model state can be accessed via model.state_dict().
Stateless Models
Stateless models do not store weights internally. Instead, their weights are passed as input to the forward function. Here is a minimal stateless model definition:
import torch
import torch.nn as nn
import torch.nn.functional as F
from typing import Dict
class StatelessModel(nn.Module):
def forward(self, x: torch.Tensor, weights: Dict[str, torch.Tensor]) -> torch.Tensor:
x = F.relu(F.linear(x, weights['fc1.weight'], weights['fc1.bias']))
x = F.linear(x, weights['fc2.weight'], weights['fc2.bias'])
return x
model = StatelessModel()
# Initialize weights externally
weights = {
'fc1.weight': torch.randn(50, 10),
'fc1.bias': torch.randn(50),
'fc2.weight': torch.randn(1, 50),
'fc2.bias': torch.randn(1),
}
x = torch.rand(1, 10)
pred = model(x, weights)It can be seen that there are no explicit layer definitions in the constructor. The model only implements the forward function and defines how inputs are mapped to outputs using the weights provided as external input.
It's important to note that, the concept of "statefulness" also exists in Recurrent Neural Networks. There, stateful or stateless refers to how the hidden state is handled across steps, i.e. whether it is carried over vs re-initialized.
When to Use Which?
Stateless models can be used for most problems but require manual parameter management and more boilerplate. Stateful models on the other hand are simpler and typically preferred unless decoupling parameters from the module provides a benefit. Common use cases for stateless execution include:
1) Hypernetworks: Another model generates or perturbs the weights consumed by the forward pass.
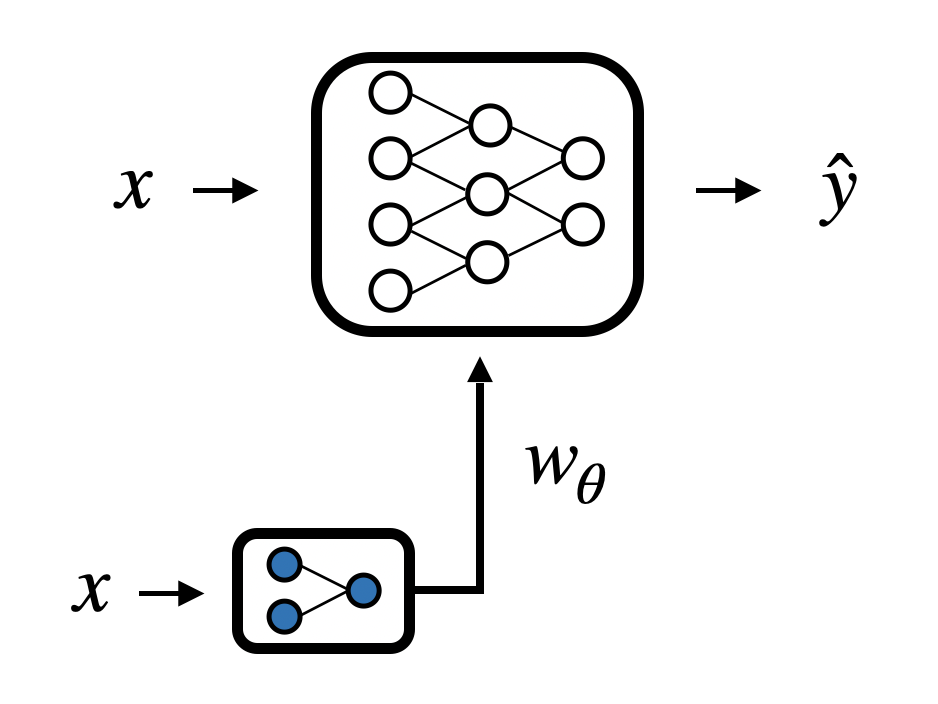
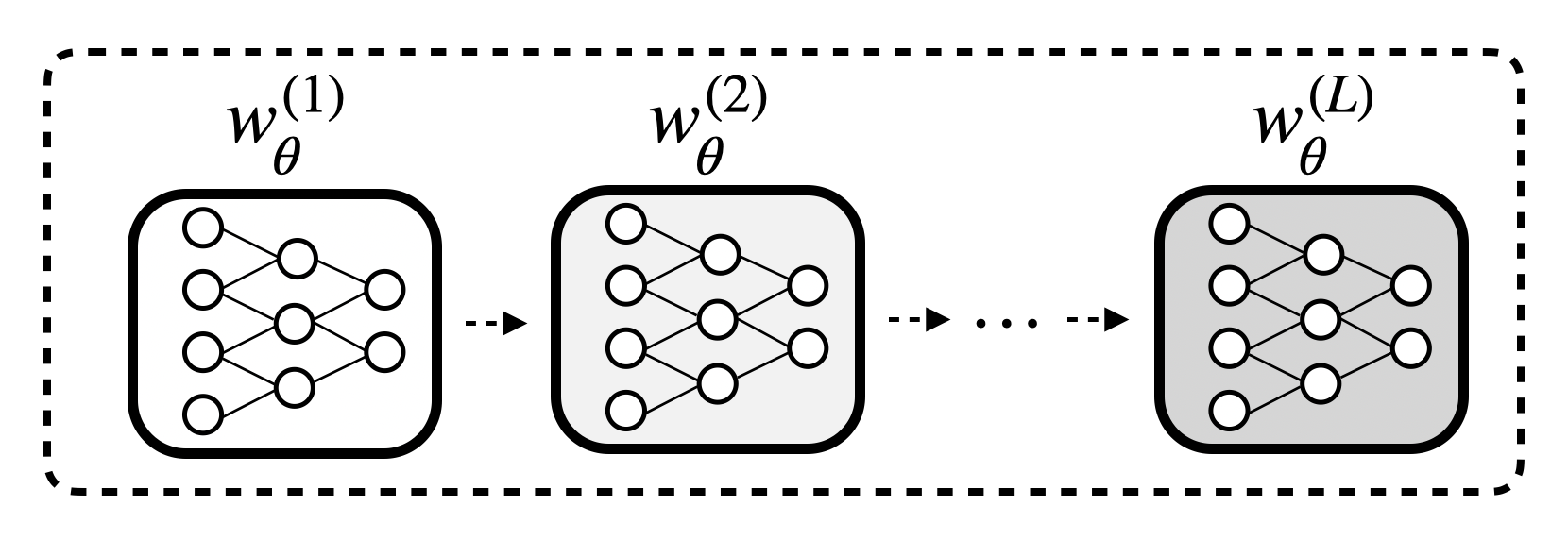
2) Meta-learning: Keeping an inner-loop computation graph intact across unrolled steps while swapping parameter sets.
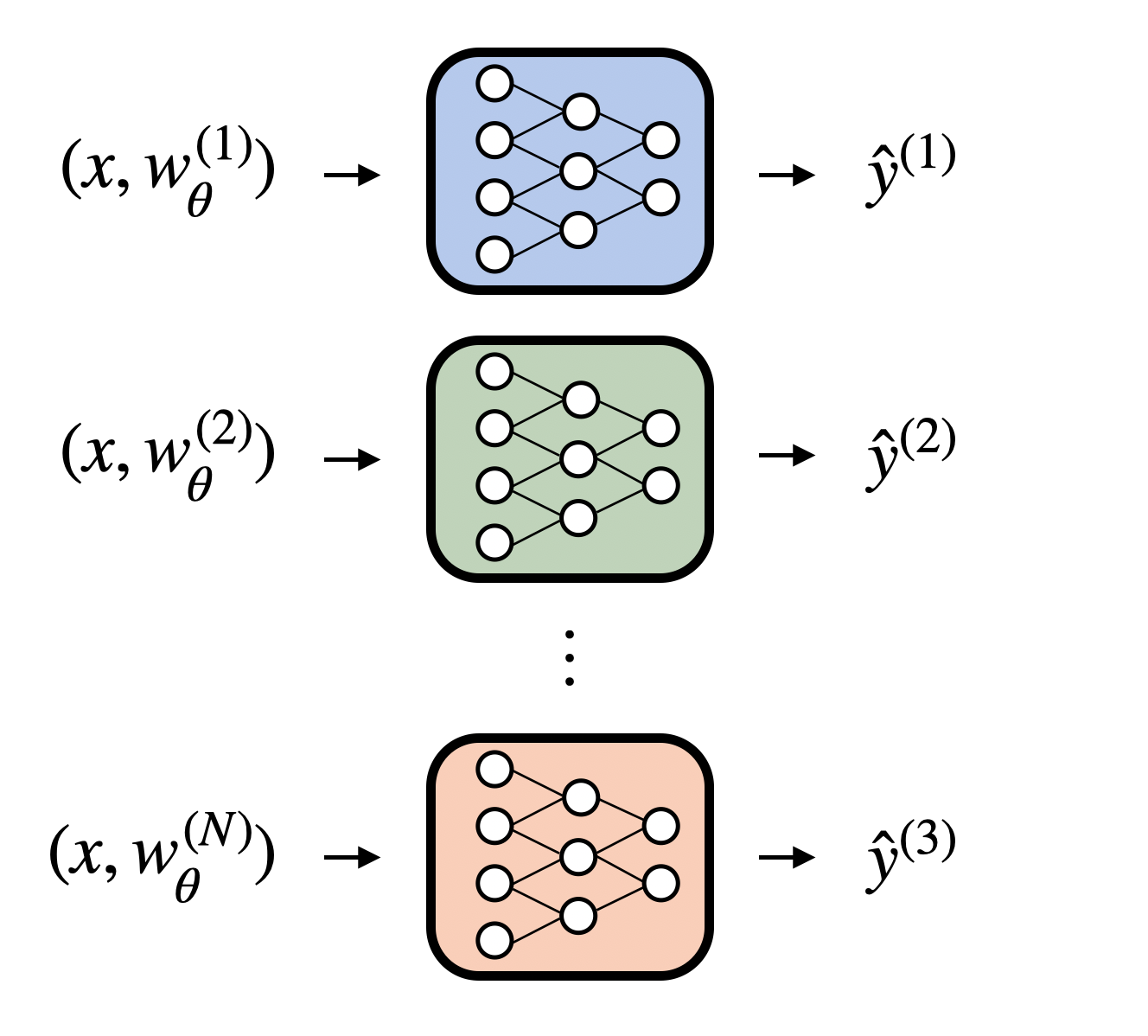
3) Ensembles: Running many parameter sets through a single forward without duplicating module instances.
Stateless Models in PyTorch (v2.0+)
Before PyTorch 2.0, one often relied on functorch or higher to “functionalize” modules. In modern PyTorch, one can use functional_call from the stateless sub-package to run a module with externally supplied parameters (and buffers) without mutating the original module.
import torch
from torch.nn.utils.stateless import functional_call
# Using the StatefulModel definition above
model = StatefulModel(10, 50, 1)
x = torch.rand(1, 10)
# Grab the model state
state_dict = model.state_dict()
# Stateless call using supplied parameters
out = functional_call(model, state_dict, (x,))
# Regular (stateful) call remains available
pred = model(x)In this example, functional_call performs a forward pass by replacing the module’s parameters and buffers with those provided as a state_dict.